# Introduction
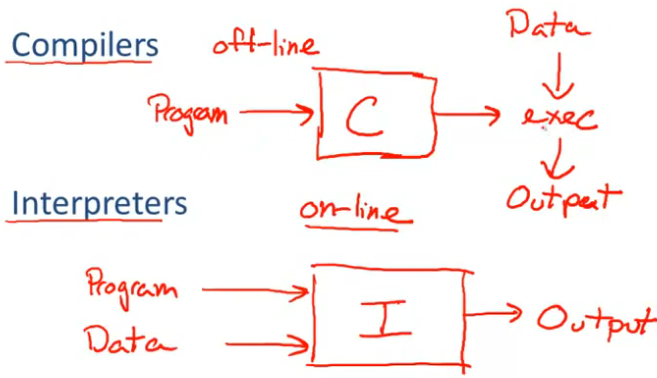
# Compilers and Interpreters
# Structure of a Compiler
The structure of a compiler contains 5 parts.
- Lexical Analysis
- Parsing
- Semantic Analysis
- Optimization
- Code Generalization
# Lexical Analysis
Lexical analysis divides program text into "words" or "tokens"(记号).
# Parsing
Parsing is to understand the sentence structure. Or parsing is diagramming sentences.
How human parsing a English sentence?
Step 1: identify the role of each words in a sentences. (词性分析)
Step 2: group the words together into higher level constructs.
Step 3: group them together and get a sentence.
# The Economy of Programming Language
Talk about 3 question.
- Why are there so many programming languages?
- Application domains have distinctive/conflicting needs.
- Why are there new programming languages?
- Programmer training is the dominant cost for a programming language.
- Widely used language will be slowly changed.
- It's easy to start a new language.
- productivity > training cost
- Language adopted to fill a void.
- Programmer training is the dominant cost for a programming language.
- What is a good programming language?
- There is no universally accepted metric for language design.
# Cool Overview
We will make a compiler: Cool -> MIPS assembly language
It contains 5 programming assignments:
- write a cool program
- lexical analysis
- parsing
- semantic analysis
- code generation
- optimization (optional)
a valid cool program
class Main { | |
i : IO <- new IO; | |
main():IO {i.out_string("Hello World!\n"); } | |
}; |
# Lexical Analysis
- Classify program into substrings according to rule.
- Communicate tokens to the parser.
A token is a pair like <token class, lexeme> to mark the class of each substrings.
An implementation must do two things:
- Recognize substrings corresponding to tokens.
- Identify the token class of each lexeme.
# Example and Lookahead
DO 5 I = 1,25
DO 5 I = 1.25
LA's goal is to partition the string. This is implemented by reading left-to-right, recognizing one token at a time.
"Lookahead" may be required to decide where one token ends and the next token begins.